Hoofdstuk 5 Lineaire regressie
We negeren de aanwezigheid van de meetfouten in \(X\) en gaan uit van de predictie obv \(W\). Hiervoor is geen substudie nodig. Voor predicties te maken is lineaire regressie voldoende, het nadeel is dat de functionele relatie niet correct wordt ingeschat, maar voor predicties is de proxy relatie voldoende. Het voordeel van lineaire regressie is dat additionele covariaten ook in rekening kunnen worden gebracht: dit kan de bias en variantie van de predicties verkleinen. Om gebruikt te worden in een transferfunctie, moeten we er zeker van zijn, dat de covariaat wel steeds ter beschikking is.
5.1 Zonder covariaten
We modelleren een lineaire relatie tussen \(Y\) en \(W\) in de training-dataset:
\[Y_i \sim N(\beta_0 + \beta_WW_i, \sigma^2)\]
##
## Call:
## lm(formula = pHH2O ~ pHCa_obs, data = data_train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.16646 -0.36315 0.00396 0.36324 2.81984
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.743026 0.011764 148.2 <2e-16 ***
## pHCa_obs 0.796047 0.001882 422.9 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5393 on 34871 degrees of freedom
## Multiple R-squared: 0.8368, Adjusted R-squared: 0.8368
## F-statistic: 1.788e+05 on 1 and 34871 DF, p-value: < 2.2e-16We maken nu een transferfunctie obv het gefitte model en passen dit toe op de test-dataset. We berekenen de coverage (% van de observaties in de test-dataset waarvoor het predictie-interval de echte waarde van pHH2O bevat) en de root-mean-square-error:
\[RMSE = \sqrt{n^{-1}\sum_i{(y_i - \hat{y}_i)^2}}\]
# transferfunctie
tf1 <- function(m, newdat) {
yhat <- predict(m, newdata = newdat,
interval = "prediction", level = .95)
return(yhat)
}
# pas de transfer-functie toe op de test-dataset
yhats <- tf1(m1, data_test)
data_test1 <- cbind(data_test, yhats)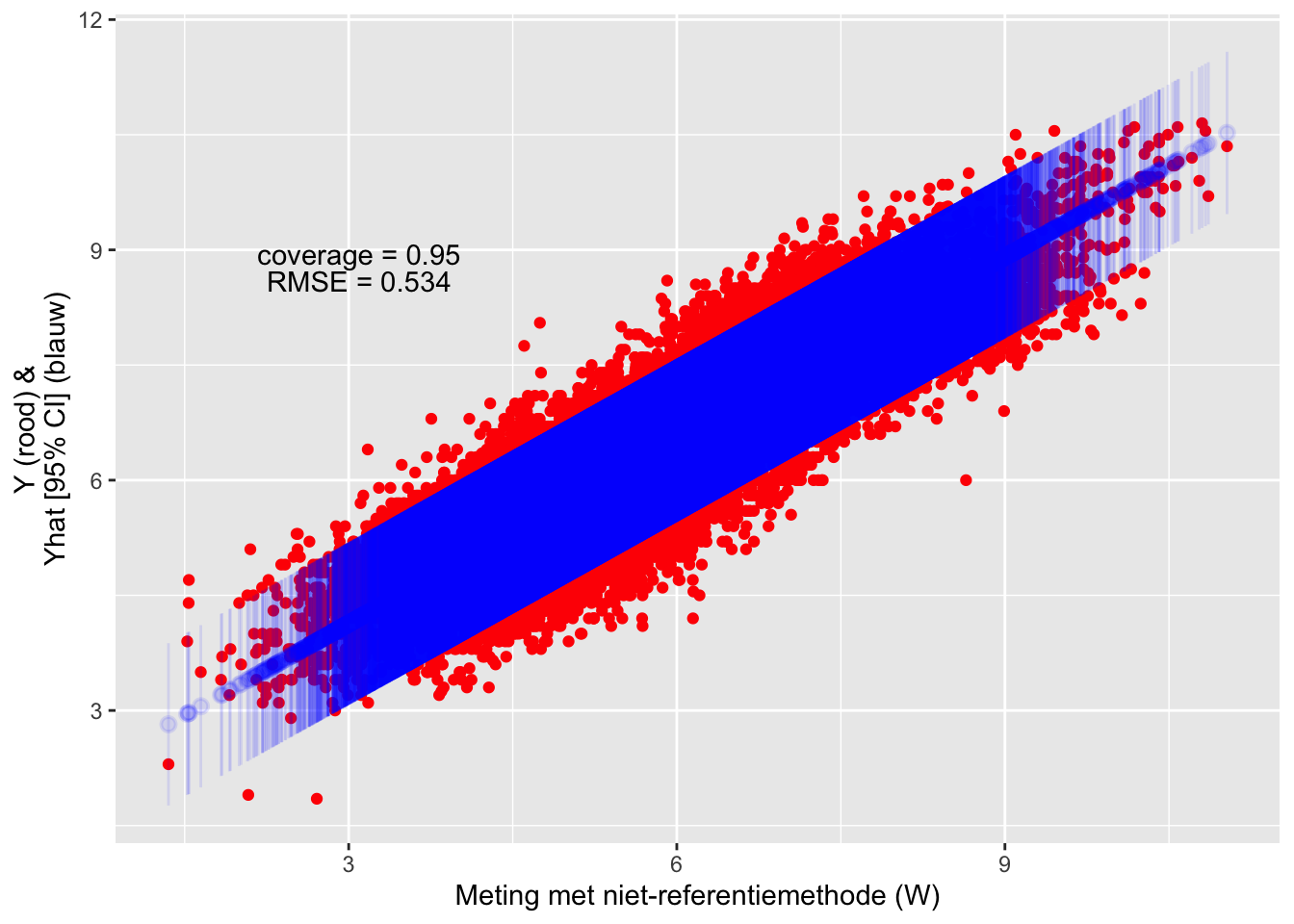
(#fig:eval_linreg1)Evaluatie van de test-dataset met de transferfunctie.
5.2 Met covariaten
We voegen nu een covariaat toe aan het model:
\[Y_i \sim N(\beta_0 + \beta_WW_i + \beta_ZZ_i, \sigma^2)\]
##
## Call:
## lm(formula = pHH2O ~ pHCa_obs + bulk_dens, data = data_train)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2.11027 -0.36267 0.00275 0.36178 2.88807
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.466913 0.018764 78.18 <2e-16 ***
## pHCa_obs 0.790495 0.001896 416.94 <2e-16 ***
## bulk_dens 0.201238 0.010689 18.83 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.5366 on 34870 degrees of freedom
## Multiple R-squared: 0.8385, Adjusted R-squared: 0.8385
## F-statistic: 9.051e+04 on 2 and 34870 DF, p-value: < 2.2e-16De coverage blijft hetzelfde en de RMSE is een beetje kleiner geworden:
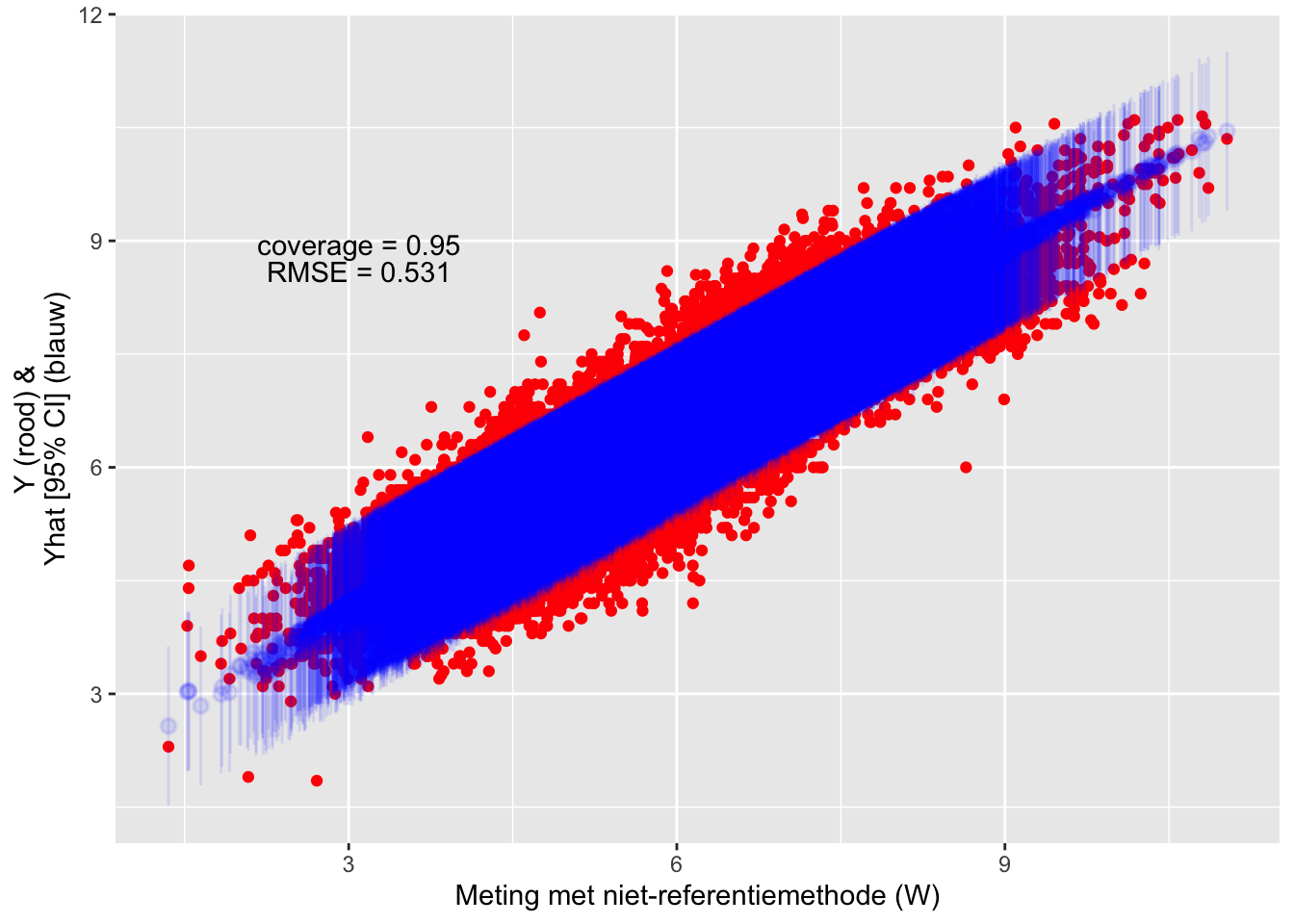
(#fig:eval_linreg2)Evaluatie van de test-dataset met de transferfunctie.
5.3 Correctie via ICC
Het lineaire regressie-model kan perfect dienen als transferfunctie en geeft unbiased predicties. Indien we naast predicties ook geïnteresseerd zijn in een schatting voor \(\beta_X\), dan zijn de modellen wel gebiased: \(\hat{\beta}_W \neq \hat{\beta}_X\). Frost & Thompson (2000) presenteren verschillende methoden om in het geval van simpele lineaire regressie zonder extra covariaten een correctie-factor \(\lambda\) te schatten die gebruikt kan worden om te corrigeren voor meetfouten in de predictor: \(\hat{\beta}_X = \hat{\lambda} \hat{\beta}_W\). De methode die uit hun simulaties als meest efficiënt naar voor komt en die makkelijk in gebruik is, is die op basis van de Intra-Class-Correlation (ICC; \(\hat{\lambda} = ICC^{-1}\)). De ICC kunnen we schatten obv een substudie met herhaalde metingen: we fitten daarvoor een linear mixed-effects model met random intercepts voor locatie. We gebruiken het lme4 package (Bates et al., 2026).
# zet de dataset in long-format
data_sub_train_long <- data_train %>%
st_drop_geometry() %>%
filter(substudy == 1) %>%
select(layer_id, pHCa_obs, pHCa_obs2, pHCa_obs3) %>%
pivot_longer(c(pHCa_obs, pHCa_obs2, pHCa_obs3),
names_to = "replicate", values_to = "pHCa_obs")
# linear mixed effects model
# fit met REML want we zijn geïnteresseerd in de variantie-componenten
lmer_replicates <- lmer(
pHCa_obs ~ 1 + (1|layer_id),
REML = TRUE,
data = data_sub_train_long
)
summary(lmer_replicates)## Linear mixed model fit by REML ['lmerMod']
## Formula: pHCa_obs ~ 1 + (1 | layer_id)
## Data: data_sub_train_long
##
## REML criterion at convergence: 27660.3
##
## Scaled residuals:
## Min 1Q Median 3Q Max
## -3.3013 -0.5596 0.0086 0.5495 2.8531
##
## Random effects:
## Groups Name Variance Std.Dev.
## layer_id (Intercept) 2.0193 1.4210
## Residual 0.2965 0.5445
## Number of obs: 10461, groups: layer_id, 3487
##
## Fixed effects:
## Estimate Std. Error t value
## (Intercept) 6.07763 0.02465 246.6Frost & Thompson (2000) presenteren ook de methode om een 95% CI te berekenen voor \(\hat{\beta}_X\) die zowel rekening houdt met de onzekerheid op de correctie-factor als met de onzekerheid in het lineair model (obv Fieller’s theorema). We passen dit hieronder toe. De schatting ligt zeer dicht bij de waarde van 0.912 in de volledige dataset en het 95% CI omvat de echte waarde (zie hoofdstuk data).
# extraheer de ICC uit het model
RE.cov <- as.data.frame(VarCorr(lmer_replicates))
ICC <- RE.cov$vcov[1] / sum(RE.cov$vcov)
lambda_hat <- 1/ICC
# pas de correctie-factor toe op de schatting uit model `m1`
beta_X_hat <- coef(m1)[2] * lambda_hat
# Fieller's methode voor 95% CI:
n <- length(unique(data_sub_train_long$layer_id))
var_lambda_hat <- (lambda_hat^2 - 1)^2 / n
var_invlambda_hat <- var_lambda_hat / lambda_hat^4
f0 <- unname(coef(m1)[2])^2 - qnorm(.975)^2 * vcov(m1)[2,2]
f1 <- unname(coef(m1)[2]) / lambda_hat # negeer covariantie studie & substudie
f2 <- 1 / lambda_hat^2 - qnorm(.975)^2 * var_invlambda_hat
beta_X_hatCI <- (f1 + c(-1, 1) * sqrt(f1^2 - f0*f2)) / f2
tibble(
estimate = beta_X_hat,
ll = beta_X_hatCI[1],
ul = beta_X_hatCI[2]
) %>% knitr::kable()| estimate | ll | ul |
|---|---|---|
| 0.9129189 | 0.9036532 | 0.9223365 |
In dit voorbeeld hebben we gewerkt met een substudie met herhaalde metingen waarbij elke locatie een vast aantal herhaalde metingen had (3), maar voor de schatting van de ICC is dit niet per se nodig; de verschillende locaties kunnen een variabel aantal herhaalde metingen hebben. Het vast aantal herhaalde metingen hebben we gekozen omdat sommige functies uit het mecor package (zie verder) dit vereisen. Ik heb nog niet kunnen achterhalen of deze methode ook kan gebruikt worden (mits aanpassingen) indien we werken met verschillende predictoren.